
IA
Cómo funciona un LLM explicado sin jerga para pymes
Explicamos cómo funciona un LLM con una metáfora sencilla: libros, tokens, mapas de conexiones y millones de correcciones. Sin jerga, con ejemplos reales.
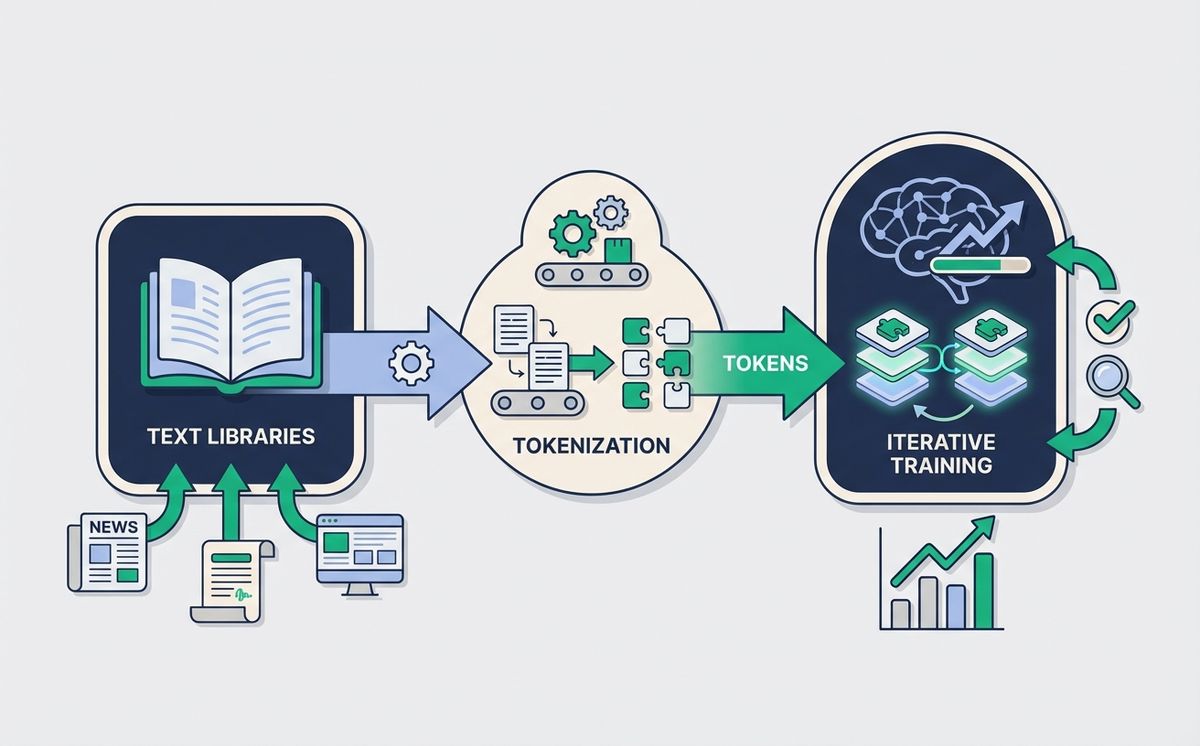
¿Cómo funciona un LLM? Imagina que tienes una máquina del tiempo y una tarde libre. La usas para ir a cada biblioteca del planeta, escanear cada libro, cada carta, cada acta notarial, y de vuelta en casa descargas toda la internet. Borras los duplicados, arreglas las erratas, y todo ese montón de texto se lo das a un programa. El programa lo rompe en trocitos muy pequeños, los conecta entre sí y aprende a adivinar qué palabra va después de cuál. Millones de veces. Cada error, corregido. Cuando ya casi nunca falla, le pides que escriba por ti y el resultado suena como un humano.
Eso, dicho sin adornos, es cómo funciona un LLM. Modelo de Lenguaje Grande, en inglés *Large Language Model*, el tipo de IA que hay detrás de ChatGPT, Claude, Gemini y todo lo que tu cuñado llama “la inteligencia artificial”.
Te voy a contar el resto de la historia en los próximos 10 minutos de lectura. Vas a entender por qué un LLM se equivoca cuando le pides datos reales, por qué acierta cuando le pides un borrador, y sobre todo vas a saber qué puedes pedirle a la IA en tu pyme y qué no. Sin jerga innecesaria, pero con los nombres correctos de las cosas. Si ya te has peleado con ChatGPT o Claude para el trabajo y quieres una base antes de seguir, puedes echarle un ojo a nuestra comparativa práctica de Claude y ChatGPT cuando acabes este artículo.
Cómo funciona un LLM: qué es, sin el marketing
Un LLM no es una persona que vive dentro de tu ordenador. Tampoco es una base de datos con todas las respuestas guardadas. Es, literalmente, una función matemática gigantesca que recibe texto y devuelve texto. Cuando escribes “la capital de Francia es”, el modelo no busca la respuesta en ningún sitio. Calcula cuál es la palabra más probable que viene después. La palabra “París” gana porque, en los billones de frases que ha leído, esa secuencia aparecía mucho.
La palabra clave aquí es probabilidad. Un LLM no “sabe” que París es la capital de Francia. Sabe que, estadísticamente, después de “la capital de Francia es” viene “París” con una probabilidad muy alta. Es una distinción sutil pero importante, y es la razón por la que a veces acierta y a veces se inventa las cosas con la misma seguridad.
Marta, directora de una agencia inmobiliaria de ocho personas en Zaragoza, aprendió esa lección por las malas. En 2024 le pidió a ChatGPT precios medios de alquiler en su barrio para una presentación a un cliente. El modelo le devolvió cifras muy convincentes: 780 euros por un piso de dos habitaciones, 1.050 por uno de tres. Sonaba razonable. Cuando el cliente cruzó los datos con el INE, resultó que las cifras estaban infladas un 30%. Marta dejó de usar IA durante casi un año. Luego entendió por qué había pasado y volvió a usarla, pero solo para cosas que el modelo sí hace bien: resumir, reescribir, estructurar. No para datos reales.
Ese es el primer concepto que tienes que llevarte: un LLM no consulta, predice. Y esa predicción es tan buena como los datos con los que se entrenó y tan mala como las correlaciones casuales que aprendió por el camino.
El combustible: corpus, limpieza y por qué importa de dónde sale el texto
Todo lo que un LLM sabe se lo enseña su corpus, que es el nombre técnico de “el montón gigante de texto con el que lo entrenaron”. Para que te hagas una idea, modelos como GPT-4 o Claude Opus se entrenan con cantidades de texto que se miden en billones de palabras. Toda Wikipedia. Miles de millones de páginas web. Libros enteros, tanto clásicos como técnicos. Foros, repositorios de código, papers científicos, guiones de películas.
Antes de meter ese corpus en el modelo hay una fase de limpieza que mucha gente ignora y que es crítica. Los ingenieros eliminan duplicados, porque un texto repetido mil veces le enseñaría al modelo que esa frase es la norma. Filtran contenido de muy baja calidad, como spam, scrapes rotos o páginas autogeneradas sin sentido. Aplican reglas para quitar datos personales evidentes, aunque siempre se cuela algo. En los laboratorios serios, esa fase de curado ocupa más tiempo y más dinero que el propio entrenamiento matemático.
Aquí viene una conclusión que rara vez se cuenta. Como el LLM aprende solo de lo que le das, los sesgos de tu corpus se convierten en los sesgos de tu modelo. Si el 70% del texto es en inglés y en registro técnico, tu modelo será mejor en inglés y en registro técnico. Si los documentos médicos son abundantes pero los contratos notariales españoles apenas aparecen, el modelo responderá con precisión a una consulta clínica y se inventará cláusulas cuando le pidas un contrato. No es malicia. Es estadística pura.
Para los laboratorios, el corpus de entrenamiento es un activo estratégico. Por eso Anthropic, OpenAI y Google se cuidan mucho de no revelar exactamente qué han metido dentro. Es una de las diferencias más importantes entre un modelo y otro, mucho más que el número de parámetros del que tanto se habla en marketing.
Trocear el lenguaje: tokens, números y un mapa gigante de palabras
Un ordenador no entiende palabras. Entiende números. Antes de que el texto llegue al modelo, pasa por una fase llamada tokenización, que convierte cada trozo de texto en un número. Un *token* puede ser una palabra completa (“perro”), una parte de una palabra (“ción”) o incluso un signo de puntuación. Los modelos modernos suelen trabajar con vocabularios de entre 30.000 y 200.000 tokens distintos.
Cuando tú escribes “hola, ¿cómo estás?”, el modelo no ve esa frase. Ve algo parecido a esta secuencia: [15496, 11, 17594, 34, 29326, 27315]. A partir de ahí, cada número se transforma en un embedding, que es un vector con cientos o miles de dimensiones. Piensa en un vector como una lista muy larga de coordenadas. Cada token vive en un espacio matemático enorme, y los tokens con significados parecidos se colocan cerca. “Rey” queda cerca de “reina”, “Madrid” queda cerca de “Barcelona”, y entre todos forman un mapa gigante de relaciones.
Sobre ese mapa actúa la arquitectura que lo cambió todo en 2017: el transformer. La referencia canónica es el paper Attention Is All You Need de Vaswani y su equipo en Google. El transformer introduce un mecanismo llamado *atención*, que permite que cada token mire a todos los demás de la frase a la vez y decida cuáles son relevantes para entenderlo. Es como leer una frase larga y marcar con fosforito las palabras que más influyen en lo que estás procesando en ese momento. Esa capacidad de ver el contexto completo, en paralelo y a gran escala, es lo que permite generar respuestas coherentes.
Si quieres una intuición visual muy buena sobre cómo funcionan estos vectores por dentro, la serie de redes neuronales de 3Blue1Brown es posiblemente la mejor explicación gratuita que existe en internet. No hace falta saber matemáticas para disfrutarla. Si en cambio prefieres aterrizar esta teoría en código, el curso gratuito de Hugging Face te permite tokenizar texto con un par de líneas de Python en menos de quince minutos.
Adivinar la siguiente palabra, diez billones de veces
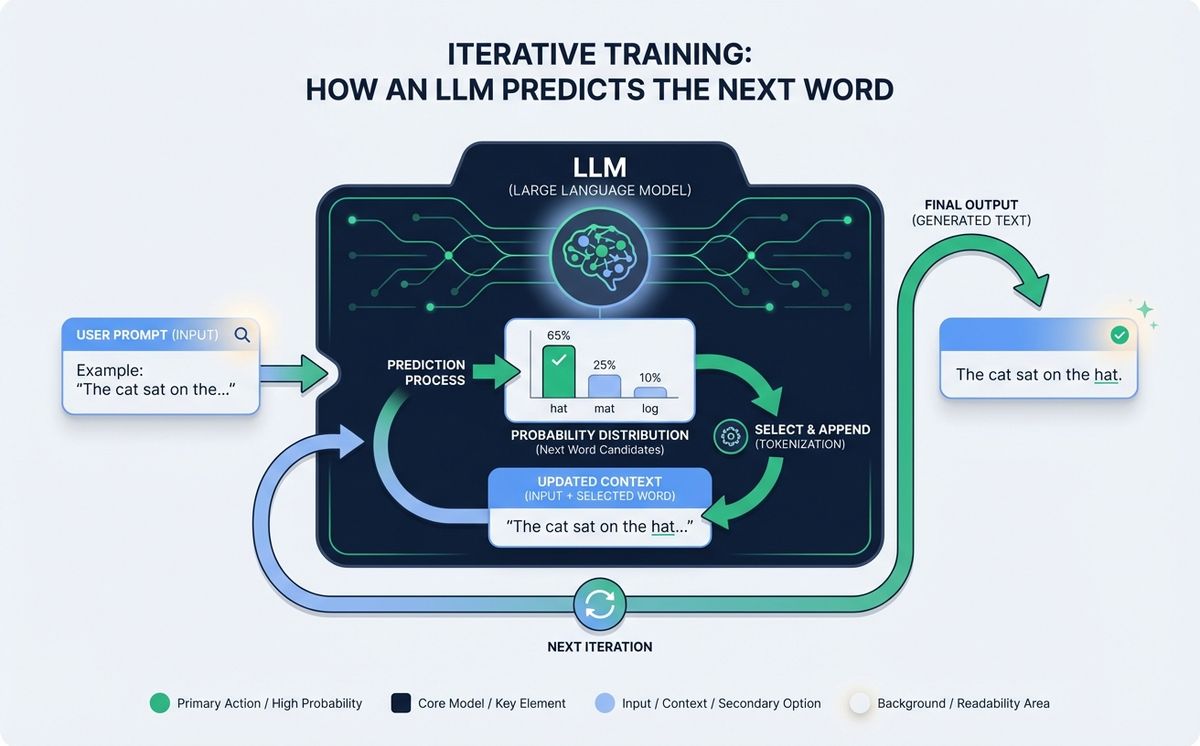
Con el corpus preparado y el texto tokenizado, llega el paso más largo: el entrenamiento. El objetivo es ridículamente simple. Al modelo se le muestra una frase con la última palabra tapada y se le pide que adivine cuál es. Si adivina bien, se refuerzan las conexiones que llevaron a esa respuesta. Si falla, se ajustan los pesos internos para que la próxima vez falle un poquito menos. Ese ajuste se llama *backpropagation*, que es el nombre técnico de “alguien tachando tu error con un boli rojo y apuntando al margen cómo tenías que haberlo hecho”.
Vamos a un ejemplo concreto. El modelo ve la frase “El sol sale por el” y tiene que predecir la siguiente palabra. La primera vez, antes de haber aprendido nada, responde “oeste”. Una función matemática le dice “no, era este”. Los pesos asociados a la conexión entre “sol sale por el” y “oeste” bajan un poquito. Los asociados a “este” suben un poquito. Ahora multiplica este proceso por billones de frases, por años de cálculo en clusters de GPUs que consumen electricidad como un edificio de oficinas, y empiezas a tener una idea del coste real de entrenar un modelo grande. Los ingenieros hablan de *épocas*, de *learning rate*, de *gradientes*. Nosotros podemos traducirlo como: cada vez que el modelo se equivoca, corrige un poquito. Repetirlo muchas, muchas veces. Eso es todo.
La parte que suele sorprender es que este proceso, aplicado a una escala salvaje, hace emerger capacidades que nadie programó explícitamente. El modelo no aprende “gramática española” como un concepto. Aprende que después de un sujeto suele venir un verbo concordado. Nadie le enseña “código Python”. Aprende que después de def suele venir un nombre de función, dos puntos y un bloque indentado. No hay reglas escritas. Solo patrones.
¿Te ha quedado claro el mecanismo pero no sabes cómo llevarlo a tu empresa? Esa es justo nuestra zona. En LetBrand ofrecemos consultoría de IA y automatización enfocada a pymes que quieren dejar de usar ChatGPT como juguete y empezar a integrarlo en flujos de trabajo reales. Sin pitch, sin promesas vacías.
Por qué un LLM puede inventar sin saber que miente
Con todo lo anterior en mente, las famosas alucinaciones dejan de ser misteriosas. Un LLM no tiene un módulo interno que diga “esto lo sé con certeza” y otro que diga “esto me lo estoy inventando”. Para el modelo, generar la respuesta correcta y generar una invención coherente es exactamente el mismo proceso: calcular qué palabra viene después con más probabilidad. Si la respuesta correcta aparecía muchas veces en su entrenamiento, la generará. Si no, generará la secuencia que más se le parezca, y sonará igual de segura.
Por eso los LLMs se equivocan en cosas raras. Inventan citas bibliográficas con autores reales, títulos plausibles y DOIs que no existen. Citan jurisprudencia que nunca ocurrió. Dan estadísticas con decimales y todo, pero sin fuente verificable. No es que estén mintiendo en el sentido humano. No pueden mentir porque no saben qué es verdad. Solo generan texto probable.
Hay varias técnicas para mitigar esto. RAG (Retrieval Augmented Generation) conecta el modelo con una base de datos que sí contiene información verificada, y obliga al modelo a citar solo lo que encuentra ahí. Los *agentes de IA* pueden llamar a herramientas externas para comprobar hechos antes de responder. Si te interesa el tema de agentes, en nuestra guía de cómo crear un agente de IA desde cero lo desarrollamos a fondo. También están los modelos con razonamiento extendido, que se toman más tiempo para autoverificar antes de responder.
Pero el principio sigue siendo el mismo: un LLM no sabe nada. Predice. Cuando te dé una respuesta importante, verifícala. Siempre. Sin excepción. Esa actitud, por sí sola, distingue a las pymes que sacan partido a la IA de las que se pillan los dedos.
Lo que todo esto significa para tu pyme
Ahora la parte que de verdad importa. ¿Qué hago con esto mañana en mi empresa? Entender el mecanismo te da tres cosas muy prácticas.
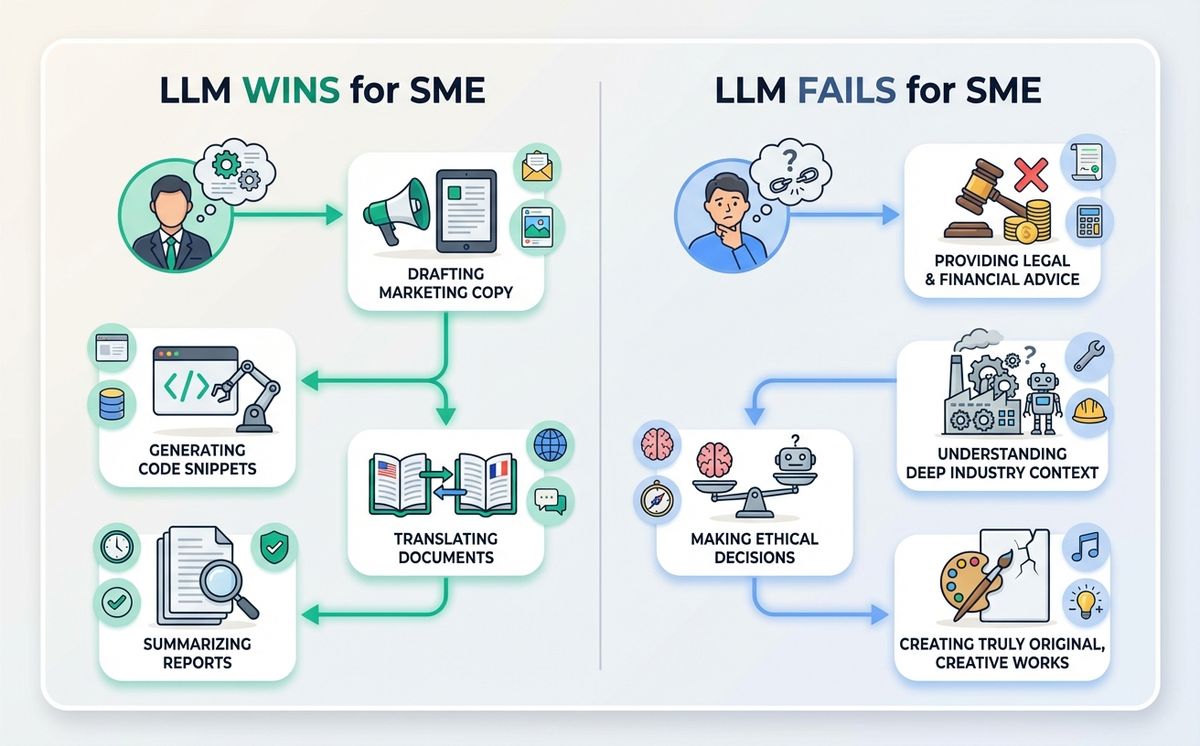
La primera es un filtro para decidir en qué tareas puedes confiar en el modelo y en cuáles no. Las tareas donde un LLM brilla son aquellas en las que tú aportas el contenido y el modelo aporta la forma: resumir un email de cliente, reescribir un texto con un tono concreto, traducir manteniendo matices, generar un borrador de propuesta comercial a partir de tus notas, clasificar tickets de soporte, limpiar datos desordenados. En todas ellas, el modelo no tiene que acordarse de nada. Solo transforma lo que le das.
Las tareas donde un LLM falla son las que requieren información reciente, datos verificables o decisiones con consecuencias reales sin supervisión. Precios actuales, normativa vigente, jurisprudencia, cifras de tu CRM, decisiones legales. Ahí, o conectas el modelo con una fuente de datos viva mediante RAG o agentes, o te pillas los dedos como Marta.
La segunda cosa que ganas es expectativas realistas sobre los proveedores. Cuando alguien te venda “IA que toma decisiones autónomas en tu empresa”, ahora sabes que eso requiere arquitectura seria: agentes, herramientas conectadas, verificación, logging, supervisión humana. No es magia. Es ingeniería. El precio debería reflejar eso. Si es barato, suele significar que estás comprando un prompt bien puesto sobre un modelo estándar, nada más. Si quieres evaluar herramientas open-source antes de meterte con vendors cerrados, nuestra pieza sobre qué es OpenClaw te da un buen punto de partida.
Javier, CTO de una startup logística con 15 empleados en Valencia, hizo exactamente ese ejercicio el año pasado. Dejó de pedirle a la IA que “tomara decisiones” y empezó a pedirle que ordenara información y redactara borradores. Montó tres flujos muy tontos con Claude y un par de scripts: uno que resume los emails entrantes por prioridad, otro que genera los borradores de respuesta para que el equipo solo tenga que retocarlos, y un tercero que etiqueta incidencias repetidas para detectar patrones. Su equipo ahorra ahora 12 horas semanales. Nadie revisa datos inventados porque la IA nunca los genera: solo trabaja con el texto que el equipo ya ha escrito.
La tercera cosa que ganas es vocabulario para hablar con proveedores técnicos. Saber qué es un token, qué es un embedding, qué es una ventana de contexto y qué significa *fine tuning* te permite tener una conversación adulta con quien te esté vendiendo una solución. No vas a construir el modelo tú, pero vas a poder hacer las preguntas correctas.
Una idea final antes de que cierres la pestaña
Si llegaste hasta aquí, ahora entiendes cómo funciona un LLM mejor que el 95% de las personas que usan uno a diario. Recapitulando lo que nos llevamos.
- Un LLM es una función matemática que predice la siguiente palabra, no una base de datos de respuestas.
- Aprende de un corpus enorme de texto, y los sesgos del corpus se convierten en los sesgos del modelo.
- Rompe el texto en tokens, los convierte en vectores y trabaja con un mapa gigante de relaciones entre ellos.
- Se entrena fallando y corrigiendo miles de millones de veces, hasta que casi nunca falla.
- No sabe qué es verdad. Predice lo más probable. Por eso alucina, y por eso hay que verificar lo importante.
- En tu pyme, úsalo para transformar texto que tú aportas. Evítalo para aportar datos que no puedas verificar.
Si después de leer esto piensas que hay flujos en tu negocio que encajan y otros que no, y quieres una opinión honesta sobre por dónde empezar, podemos tener una conversación sin compromiso. En LetBrand llevamos años ayudando a pymes a meter IA en sus operaciones sin promesas de humo. Reserva una llamada de 30 minutos (gratis, sin pitch) para auditar qué partes de tu negocio tienen sentido automatizar con IA y te contamos con honestidad si merece la pena o no. A veces la respuesta es que todavía no. Eso también es información útil.
Artículos Relacionados

Las skills para agentes son el estándar abierto que funciona con Claude Code, Copilot, Gemini CLI y 45+ agentes de IA. Un archivo. Todas las herramientas.
Leer más
Cada fin de semana de partido, Cloudflare bloqueado en España tumba tiendas online, pagos y apps. Los piratas ven el partido. Tu negocio paga la factura.
Leer másListo para empezar tu proyecto?
Hablemos de cómo podemos ayudar a tu marca a crecer con una estrategia digital personalizada.
Contáctanos